A Brief Guide To Finding Missing Data
A mission for me recently has been finding more interesting datasets for machine learning and AI than the ones that are widely available. If it’s text, it’s usually Hemingway or Shakespeare, and if it’s images, it’s usually people who, well, look exactly like me.
The issue with the data that goes into the many algorithms that are infecting are lives is well-documented: they know a lot about white guys, and very little about anyone else. It’s possible that these systems will remain racist regardless of their data as long as white men are the people making them, but in many cases we simply don’t have the data to find out. There are lots of structural reasons for this that I won’t dive into here, but it’s very clearly a problem.
At any rate, when I got the chance to work on collecting some of these missing datasets for Ayo Okunseinde and Nikita Huggins, I jumped at it, and I learned a lot along the way. They’re working on machine learning projects around data from authors of color — right now, James Baldwin and Octavia Butler — and, as I found out quickly, this data isn’t widely available. So how do we get it?
First Attempts: Libgen and the Baldwin Generator
If you’re trying to find writing that might otherwise be behind a paywall or not online at all, LibGen is one of your best options. It’s a search engine that will take you to PDFs or other e-versions of academic articles, novels, and more. But this process is time-consuming, especially if you’re trying to turn these articles into a .txt file for machine learning. So what’s to be done?
I started by googling to see if anyone had done the same thing before, and lo and behold someone had already written a web scraper for it! However, this one was three years out of date, and a lot of the structure of libgen’s website had changed in the interim — as with many things on the edge of internet legality, it seems to move around a lot. I adapted the script to account for these changes, and after a good bit of futzing around I wound up with my own version.
What it does:
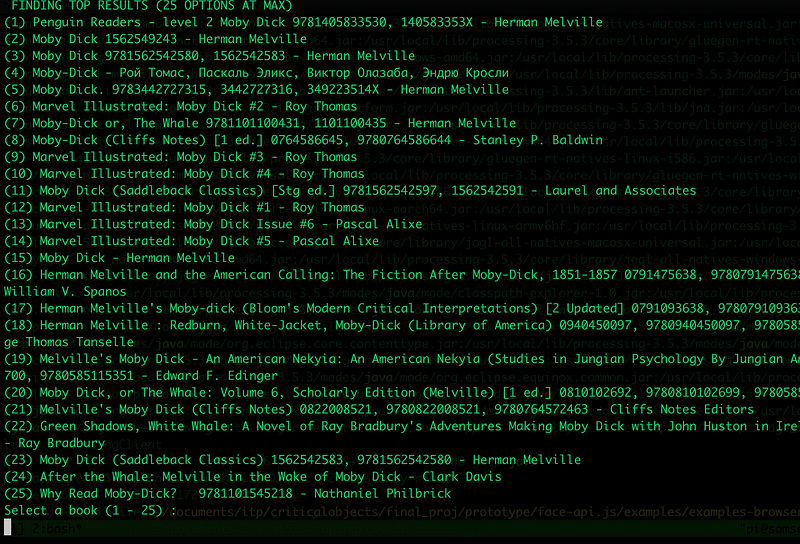
If you run ruby libgen-scraper.rb in the terminal, you’ll see the following interface:

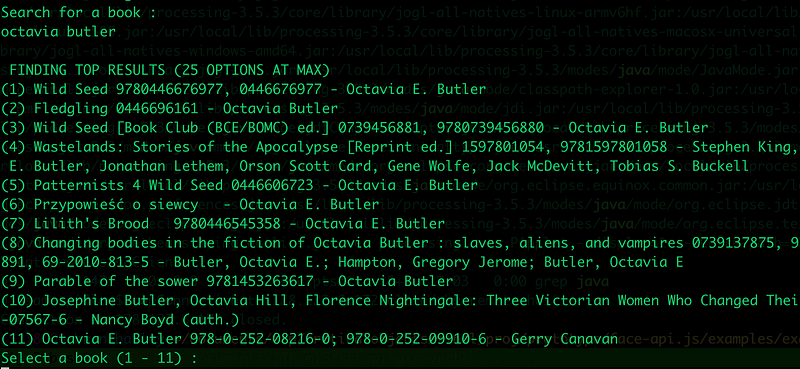
Simply type in the name or author of the book you want to find, and hit Enter.
Depending on how popular the book is, you may get a ton of results or just a few. Select the number of the result that looks like the best fit, and hit enter.

You should see something like this. It doesn’t look like it, but it’s downloading the book! If you check inside the folder you downloaded the scraper in, it will write both the .pdf and a parsed .txt version of the pdf file in there, for you to use as you see it. It’ll then prompt you to enter another book — you can repeat this cycle as many times as you’d like, or quit by hitting Ctrl + c .
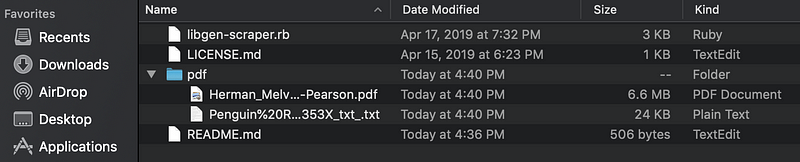
This ended up working out great for finding most of James Baldwin’s work — you can see a working prototype of an ml5 example trained on his work here, and find the model I trained in the “models” folder on the github if you’d like to try it out yourself.
Take 2: The Art of Breaking Into Files
The libgen model worked well for Baldwin — I was able to find a significant portion of his work there — but proved much harder when it came to Butler.
Though these may be out there somewhere in the ether of the internet, they weren’t easily findable by ordinary means. So, from here, we decided to get into dicier territory. We bought all the Octavia Butler books available on an unnamed ebook provider, but, as we quickly discovered, they were all DRM-protected. This meant we could only access them in the app of that ebook provider’s choice. Obviously, for the purpose of training machine learning models, this is pretty unacceptable — the text is only accessible within a specific application, and cannot be converted to a standard text format for model training.
NOTE: this was all done in an academic context — depending on the agreement you may have with your eBook provider, this may or may not fall under your rights as a purchaser.
The tools for an aspiring model trainer in this context are three: the Calibre ebook manager, Apprentice Alf’s De-DRM tools, and a little script I wrote to convert EPUB files to .txt files (if you want to do this on a different type of file, feel free to adapt the script/pull request it/message me if you have any issues).
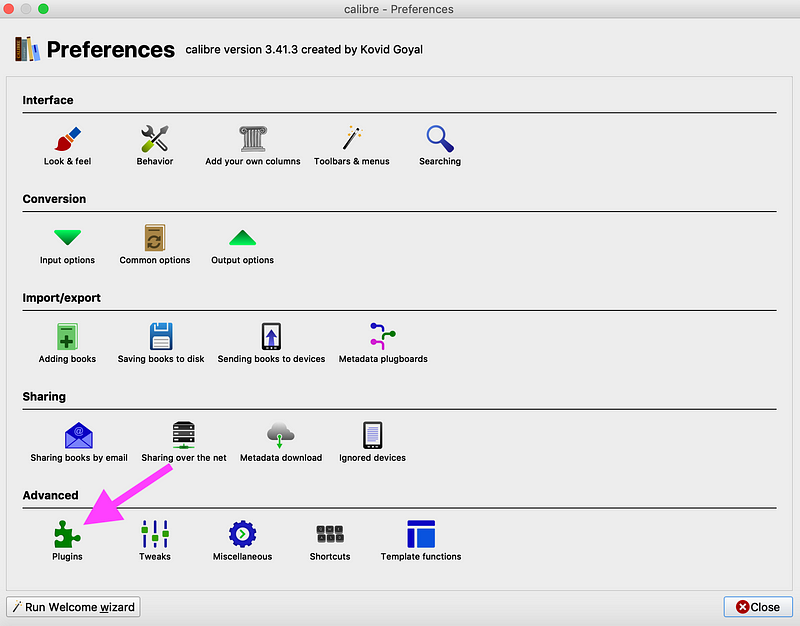
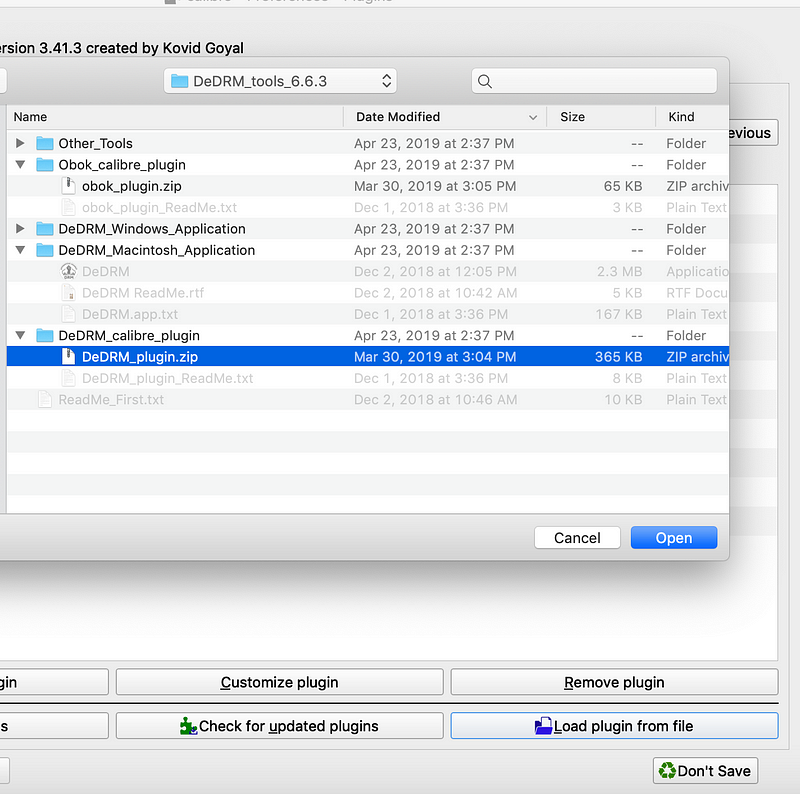
You can download Calibre here. Once it’s downloaded, you can download the DRM removal tools here. Unzip that package, then run Calibre. In the menu bar, hit Preferences, then hit Preferences in the pop-up menu. The menu below should appear. Click on the “Plugins” box, represented by a puzzle piece.
Hit the “load plugin from file” button on the bottom right, find the folder where you unzipped DeDRM tools, and select the DeDRM_plugin.zip file that corresponds to your operating system.
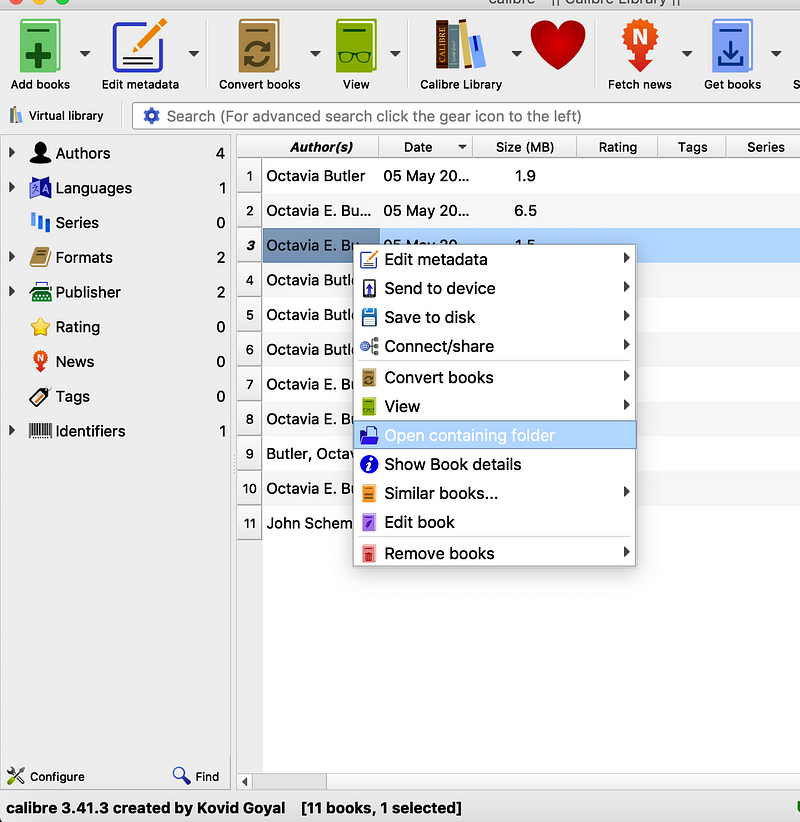
Once this is done, you should be able to drag the files from wherever your e-reader stores them (usually you can left-click on a file to see where it’s stored in your filesystem) into Calibre, and voilá! The DRM is removed. However, we still need to convert it to a .txt file. If you copy the files from Calibre (you can find them in your system by right-clicking on a book and hitting “Open containing folder”) into the “files” folder in the github repo, then run ruby converter.rb, they should be good to go!
Scraping The Images
There was one last component of this project that particularly interested me: creating a dataset of faces of color. There seem to be few publicly available face datasets that don’t, inevitably, end up creating white faces. This is a problem on just about every level. But how do we make a new dataset?

If you guessed web scraping, you guessed right. We were focused on getting images from coverbrowser.com — specifically covers of Ebony and Jet.

There were over a thousand images for both, so gathering these by hand would be wildly impractical. I’d been itching to try image scraping with ScraPy and python, so this time I wrote my own artisanal scraper, on my github here.
The instructions are all on the github. This part of the project was a good bit more technically complex than the rest so I’ll document what goes into the Python script further in a more technical post, but basically this will scrape all covers for any magazine on coverbrowser, and write them to either your local system or Amazon s3, depending on how you set it up.
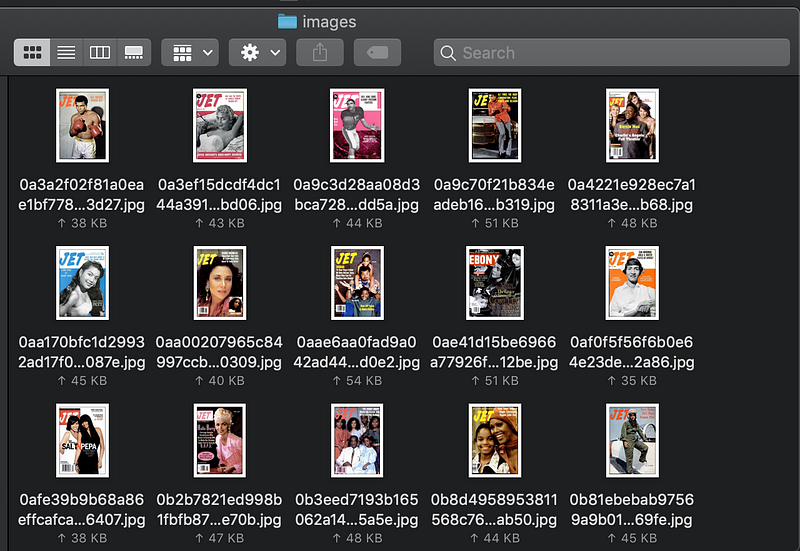
For my own use, I was able to scrape 2800 images from Ebony and Jet, which I’d call a success. If you’d like to use these images in your own work, they’re in the github repo as images.zip .
This was an excellent journey in terms of learning about scraping, which I’d never touched before. However, this is still just a small drop in the bucket, and may not be super useful for people who don’t already have a technical background. I’m hoping in the future to take this even further and work on making more accessible scraping tools. In the meantime, I’ll be continuing to look into new ways of finding missing datasets.